
Τι σηµαίνει να «διαβάζεις» ένα κείµενο; Για έναν φιλόλογο, είναι µια πράξη ερµηνείας: η αναζήτηση νοηµάτων, αποχρώσεων και υπαινιγµών. Για έναν ιστορικό, είναι ένα παράθυρο σε µια άλλη εποχή. Για τον µη ειδικό, µπορεί να είναι µια είδηση, ένα σχόλιο ή µια άποψη. Σήµερα, σε αυτή τη διαδικασία µπαίνει δυναµικά και ένας νέος «αναγνώστης»: η τεχνητή νοηµοσύνη.
Ένας αναγνώστης που δεν κουράζεται, δεν περιορίζεται σε λίγα κείµενα και µπορεί να επεξεργαστεί τεράστιες ποσότητες πληροφορίας. Μπορεί να ανιχνεύσει µοτίβα σε χιλιάδες άρθρα ή να εντοπίσει αλλαγές στον τρόπο που γράφουµε µέσα στον χρόνο.
Μιλώντας με το παρελθόν
Ας µεταφερθούµε σε ένα αρχαίο αρχείο γεµάτο χειρόγραφα. Εκεί συναντά κανείς σελίδες φθαρµένες, γραµµένες µε διαφορετικούς τρόπους, σε διαφορετικές εποχές. Μέχρι πρόσφατα, η µελέτη τους απαιτούσε χρόνια εξειδίκευσης. Σήµερα, χρησιµοποιούµε αυτή την εξειδίκευση για να «διδάξουµε» σε υπολογιστικά µοντέλα να αναγνωρίζουν τα γράµµατα από τις φωτογραφίες τους, ακόµη και όταν αυτά αλλάζουν µέσα στους αιώνες. Αυτό φαίνεται καλύτερα όµως µε µία εικόνα, όπου ένας αλγόριθµος εστιάζει στη γραφή για να χρονολογήσει τον πάπυρο (Εικόνα 1).
Η ίδια ανθρώπινη εξειδίκευση είναι απαραίτητη σήµερα και για να επικυρώσουµε τα αποτελέσµατα της «διδασκαλίας». Αυτός είναι ο λόγος που τις ανακαλύψεις αυτές οδηγούν συχνά διεπιστηµονικές οµάδες. Σε σχετική έρευνα, για παράδειγµα, εξετάζουµε πώς εξελίσσονται οι ελληνικοί χαρακτήρες στον χρόνο και πώς αυτή η εξέλιξη µπορεί να αποτυπωθεί υπολογιστικά.
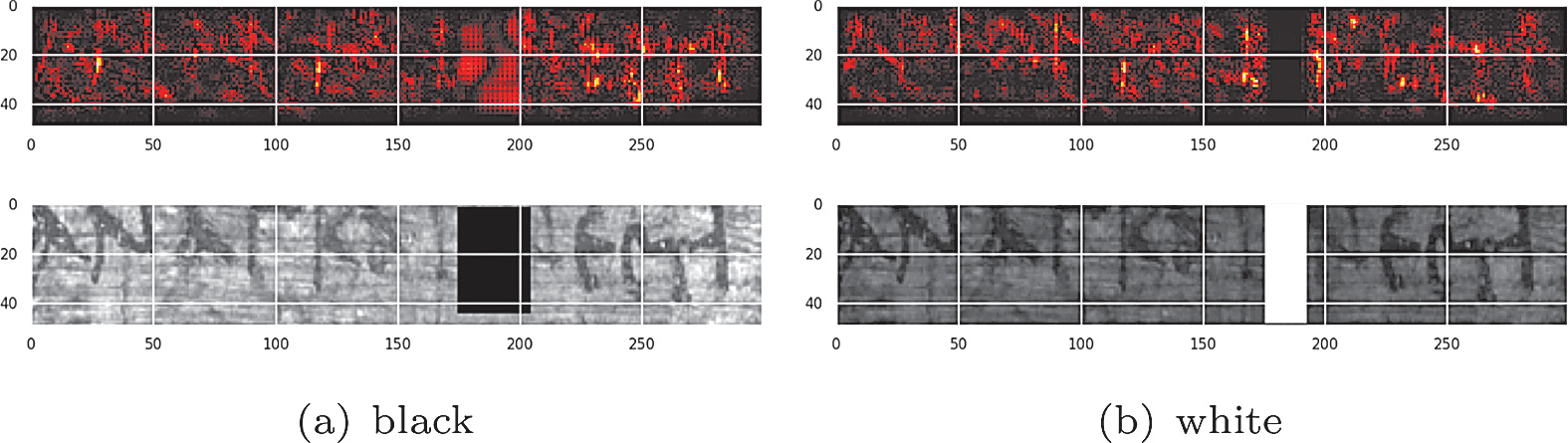
Ένας αλγόριθμος χρονολογεί έναν πάπυρο και τα κόκκινα εικονοστοιχεία (pixel) δείχνουν τα σημεία όπου εστιάζει ο αλγόριθμος για να προβλέψει τον αιώνα. Όταν τμήματα της εικόνας καλύπτονται πλήρως με μαύρο (α) κατά τη διαδικασία της πρόβλεψης, ο αλγόριθμος εξακολουθεί να εστιάζει σε περιγράμματα που θυμίζουν χαρακτήρες.
Το αποτέλεσµα; Μπορούµε πλέον να απεικονίσουµε αυτόµατα την οµοιότητα µεταξύ χαρακτήρων στους αιώνες (βλ. https://github.com/ipavlopoulos/diachronic-greek-letterforms). Η απεικόνιση αυτή θα ήταν αδύνατη χωρίς τα κατάλληλα υπολογιστικά µοντέλα, ενώ η ανάλυσή της απαιτεί εξειδικευµένη φιλολογική γνώση που προσέφερε στην περίπτωσή µας η διεπιστηµονική φύση της ερευνητικής οµάδας.
Όταν η ερμηνεία δεν είναι μία
Η τεχνητή νοηµοσύνη µπορεί να βοηθήσει µε έναν ακόµη τρόπο: µπορεί να αναγνωρίσει πώς διαφορετικοί άνθρωποι κατανοούν το ίδιο κείµενο µε διαφορετικό τρόπο. Mία απλή παροιµία, για παράδειγµα, όπως το «όποιος βιάζεται σκοντάφτει», για άλλους λειτουργεί ως συµβουλή για υποµονή, για άλλους ως ειρωνικό σχόλιο προς κάποιον που έκανε λάθος ή ως έµµεση κριτική.
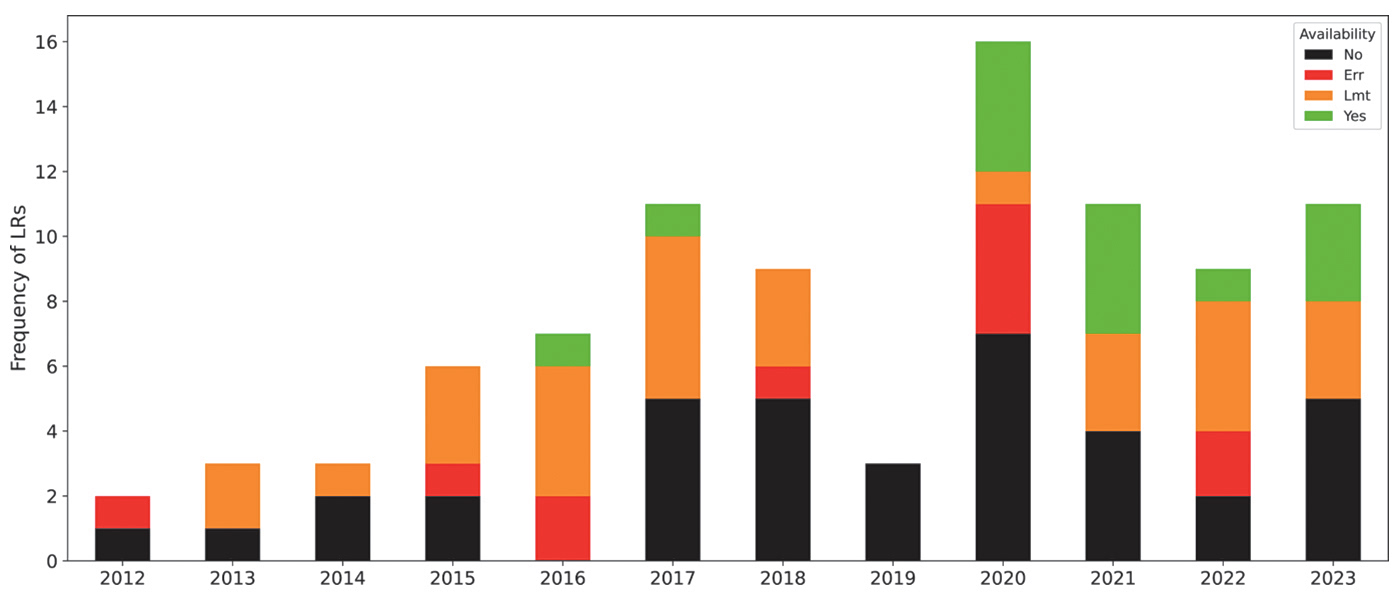
Πλήθος ελληνικών συνόλων δεδομένων και κατηγοριοποίηση της διαθεσιμότητάς τους. Τα διαθέσιμα δεδομένα (με πράσινο χρώμα) αυξήθηκαν τελευταία.
Το ίδιο σχόλιο µπορεί για κάποιους να είναι αθώο και για άλλους προσβλητικό. Η ίδια είδηση µπορεί από άλλους να εκληφθεί ως ουδέτερη και από άλλους ως µεροληπτική. Ποια είναι λοιπόν τα στοιχεία που µας κάνουν να συµφωνούµε µεταξύ µας και να διαφωνούµε µε άλλους, που πιθανώς επίσης συµφωνούν µεταξύ τους; Η κατανόηση αυτού του φαινοµένου της πόλωσης είναι ιδιαίτερα σηµαντική για την καλύτερη χρήση και εφαρµογή της τεχνητής νοηµοσύνης. Για να γίνει αυτό πιο εύκολα κατανοητό αρκεί να σκεφτεί κανείς το ανάποδο: την αγνόηση της πόλωσης.
Το αποτέλεσµα θα ήταν τα περισσότερα µοντέλα να υιοθετήσουν την άποψη που εκφράζουν οι κυρίαρχοι πόλοι, παραγκωνίζοντας τις απόψεις άλλων πόλων, ακόµη και αν είναι λογικές και βάσιµες.
Ποιος έχει τον τελευταίο λόγο;
Οι νέες δυνατότητες της τεχνητής νοηµοσύνης συνοδεύονται από ένα κρίσιµο ερώτηµα: ποιος ερµηνεύει; Τα υπολογιστικά µοντέλα βασίζονται σε δεδοµένα, τα οποία αντανακλούν προκαταλήψεις, πολιτισµικά συµφραζόµενα, και ιστορικές ανισότητες.
Επιπλέον, οι ερµηνείες µπορούν να είναι πολλές. Η τεχνητή νοηµοσύνη, λοιπόν, δεν πρέπει να επιλέγει δογµατικά «τη σωστή», αλλά να αναδεικνύει τη διαφορετικότητα. Και αυτό απαιτεί όχι µόνο τεχνικές λύσεις, αλλά και ουσιαστική συνεργασία µε τις ανθρωπιστικές σπουδές.
Μια επιλογή για το μέλλον
Για να αξιοποιήσουµε αυτή τη δυναµική, χρειάζονται συγκεκριµένες αποφάσεις. Χρειάζεται επένδυση στην ψηφιοποίηση και στήριξη διεπιστηµονικών οµάδων. Επίσης, χρειάζεται ανάπτυξη ανοικτών δεδοµένων και αξιοποίησή τους µέσα από µελέτες, εστιάζοντας στην ελληνική γλώσσα και κοιτάζοντας ευρύτερα το διεπιστηµονικό πεδίο. Ευτυχώς παρατηρούµε αύξηση τέτοιων δεδοµένων πρόσφατα, όπως φαίνεται και στο ραβδόγραµµα.
Χρειάζεται όµως και ενσωµάτωση όλων αυτών των θεµάτων στην εκπαίδευση, χτίζοντας τη διεπιστηµονικότητα στις βάσεις. Γιατί η τεχνητή νοηµοσύνη δεν πρέπει να αντικαταστήσει την ανθρώπινη εξειδίκευση, αλλά να βοηθήσει τον άνθρωπο να δει πιο καθαρά τον εαυτό του µέσα από κείµενα, εικόνες, και ιστορίες που αφήνει πίσω του.
*Του Γιάννη Παυλόπουλου, Επίκουρου Καθηγητή του Τμήματος Πληροφορικής του ΟΠΑ και Ερευνητή, Αρχιμήδης, Ερευνητικό Κέντρο «Αθηνά».
Το άρθρο δημοσιεύθηκε αρχικά στο ένθετο ΟΠΑ News του Οικονομικού Πανεπιστημίου Αθηνών που κυκλοφόρησε με «Το Βήμα της Κυριακής» την Κυριακή 28 Ιουνίου 2026.






